 at 7.19.10 AM
Added April 20, 2024
at 7.19.10 AM
Added April 20, 2024
 at 4.03.29 PM
Added April 19, 2024
at 4.03.29 PM
Added April 19, 2024
 at 9.37.53 PM
Added April 15, 2024
at 9.37.53 PM
Added April 15, 2024
 at 9.08.39 PM
Added April 15, 2024
at 9.08.39 PM
Added April 15, 2024
 at 9.05.13 PM
Added April 15, 2024
at 9.05.13 PM
Added April 15, 2024
 at 8.51.46 PM
Added April 15, 2024
at 8.51.46 PM
Added April 15, 2024
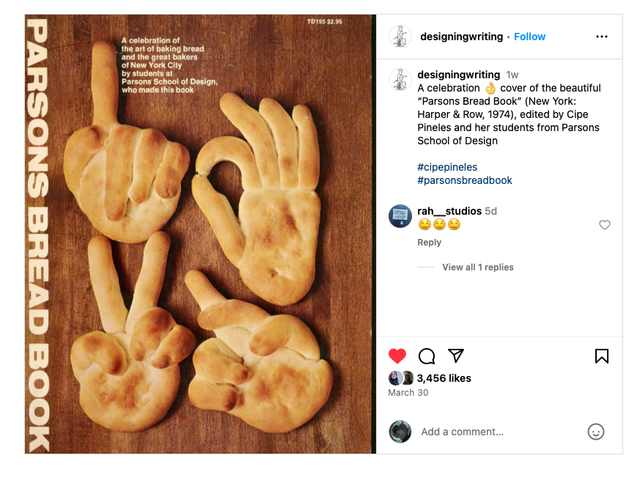 at 12.12.07 PM
Added April 8, 2024
at 12.12.07 PM
Added April 8, 2024
 at 11.41.49 AM
Added April 8, 2024
at 11.41.49 AM
Added April 8, 2024
 at 2.35.54 PM
Added April 2, 2024
at 2.35.54 PM
Added April 2, 2024
 at 2.31.21 PM
Added April 2, 2024
at 2.31.21 PM
Added April 2, 2024
 at 11.06.00 AM
Added April 1, 2024
In my solitude
Added March 28, 2024
Writing with AI
Added March 24, 2024
Design cannot be Sustainable
Added February 21, 2024
at 11.06.00 AM
Added April 1, 2024
In my solitude
Added March 28, 2024
Writing with AI
Added March 24, 2024
Design cannot be Sustainable
Added February 21, 2024
 at 2.46.55 PM
Added February 6, 2024
Martin Scorsese & Daniel Day-Lewis on Gangs of New York
Added January 29, 2024
Meaning is an Economic Unit
Added January 19, 2024
Note about Places
Added January 18, 2024
What is Work
Added January 10, 2024
Current Websites
Added January 9, 2024
Update
Added January 9, 2024
The Difference That Makes a Difference
Added January 9, 2024
it-is-hard-to-find-substack-publications-consistent-enough-to-be-worth-the-money 37wdvcx06wakf3lz
Added January 9, 2024
iframe-style-border-radius-12px dnhj9b7lzab4p5l2
Added January 9, 2024
at 2.46.55 PM
Added February 6, 2024
Martin Scorsese & Daniel Day-Lewis on Gangs of New York
Added January 29, 2024
Meaning is an Economic Unit
Added January 19, 2024
Note about Places
Added January 18, 2024
What is Work
Added January 10, 2024
Current Websites
Added January 9, 2024
Update
Added January 9, 2024
The Difference That Makes a Difference
Added January 9, 2024
it-is-hard-to-find-substack-publications-consistent-enough-to-be-worth-the-money 37wdvcx06wakf3lz
Added January 9, 2024
iframe-style-border-radius-12px dnhj9b7lzab4p5l2
Added January 9, 2024